This is the third and final piece in our Hottest Jobs in Tech series — a set of op-eds unpacking the most in-demand AI roles. I’m taking a journalistic lens to what these jobs really mean, what companies expect, and how they’re shaping the future of software.
At 2:13 a.m., the GPU cluster goes dark.
Somewhere inside a windowless data center in Virginia, a pager buzzes. The model serving layer for an AI coding assistant — one used by tens of thousands of developers — just failed. Inference queues are piling up. Every minute costs real money.
Within seconds, a message pings in Slack: “Cluster 14 is out of memory again. Rebalancing to backup nodes. ETA 10 min.”
The person typing is an AI Infrastructure Engineer. They’re part systems architect, part firefighter, part sorcerer of distributed compute.
Everyone else gets the headlines: the researchers who publish new models and the engineers who wire them into products. But this quiet class of engineers — the ones scaling, debugging, and optimizing the invisible backbone of AI — are the reason the entire boom hasn’t collapsed under its own weight. As one Director of AI Infrastructure put it to me:
“We used to worry about algorithms. Now we worry about clusters. The whole AI economy runs on how efficiently we can move data through silicon.”
Moments like this play out quietly across the industry every day. Most never make it into press releases or technical blogs, but they define the reliability we now take for granted. They also hint at something larger: a new class of engineer shaping how intelligence meets infrastructure.
What Is an AI Infrastructure Engineer?
If AI Engineers connect models to products, AI Infrastructure Engineers connect those products to the physical world.
They build and maintain the machinery that turns computation into intelligence — the hardware, systems, and orchestration that make large-scale AI possible.
Their scope runs the full stack. They manage the compute and data fabric like GPUs, TPUs, storage, and the networks that move data at terabyte scale. They design the runtime and orchestration systems that decide where every job runs, from schedulers and autoscalers to cluster managers. They oversee model serving and pipelines, deploying, monitoring, and tuning models for performance.
They also build the observability and reliability tooling that keeps everything stable — metrics, alerts, dashboards. And they translate that stability into product impact through performance engineering and enablement, turning uptime into speed, efficiency, and usable AI experiences.

“Think of us as the air-traffic controllers of AI,” says Jason, an ML Infra Lead at a fast-growing AI company. “Hundreds of models take off, land, and refuel every hour. Our job is to keep them from colliding.”
Every decision in this stack feeds into one goal: make AI run at scale without waste or downtime.
It’s a hybrid discipline born from DevOps, MLOps, and distributed systems engineering — now reassembled for the age of trillion-parameter models.
These are the builders who transform theory into throughput, keeping the world’s most advanced models running as smoothly as any other piece of software.
Origins: From DevOps to AI Ops
A decade ago, the biggest engineering challenge was not GPUs or foundation models. It was deployment. The rise of DevOps in the 2010s transformed how companies shipped software: continuous integration, automated pipelines, infrastructure as code.
But then came machine learning and DevOps suddenly wasn’t enough. Training cycles broke traditional CI/CD. Models needed versioning, monitoring, and retraining workflows. Thus came MLOps, the halfway house between data science and software reliability.
For a few years, it worked. Then 2023 hit and everything broke again.
The 2023 generative-AI surge pushed models and workloads from single-node experiments to cluster-scale operations; costs and queueing pressures spiked across the industry, especially during the H100 crunch.
DevOps pipelines, built for predictable web services, buckled under very large LLMs — often hundreds of billions of parameters or MoE architectures with trillion-scale totals — and 24/7 inference traffic. Autoscaling logic failed to anticipate real-world demand. Hyperscalers faced acute GPU availability constraints in 2023–24, and in 2025, many are reporting the bigger bottleneck is power and data-center build-outs. Training infrastructure designed for batch jobs was now being asked to serve millions of interactive users in real time. And it couldn’t keep up.
That year forced a reckoning. AI success was no longer limited by data or research talent, but by the ability to run intelligence at scale. Teams began designing their own cloud-scale AI infrastructure systems, fine-tuning schedulers, and building observability layers specifically for model workloads. They invented new ways to stretch compute, cache results, and manage costs in near-real time.
The engineers who led those transformations started using a new name for what they did — AI Infrastructure. It wasn’t a rebrand of DevOps or MLOps. It was something larger: the foundation of modern intelligence.
AI Infra Engineers are people who can bridge systems architecture, distributed computing, and AI deployment at planetary scale.
“We realized traditional DevOps playbooks didn’t translate,” said a Head of Infrastructure I met with for this piece. “A language model behaves like a living organism — it grows, it changes, it eats compute. You can’t just wrap it in Docker and call it a day.”
These engineers built their own playbooks. They stitched together container orchestration (Kubernetes, Slurm, Ray), GPU scheduling logic, and fine-grained observability tools. They optimized tensor parallelism the way DevOps once optimized build times.
Internally, the teams that once called themselves “MLOps” quietly rebranded: AI Infra. The distinction didn’t seem to be cosmetic, but cultural. Instead of managing pipelines, they were managing supercomputers in disguise.
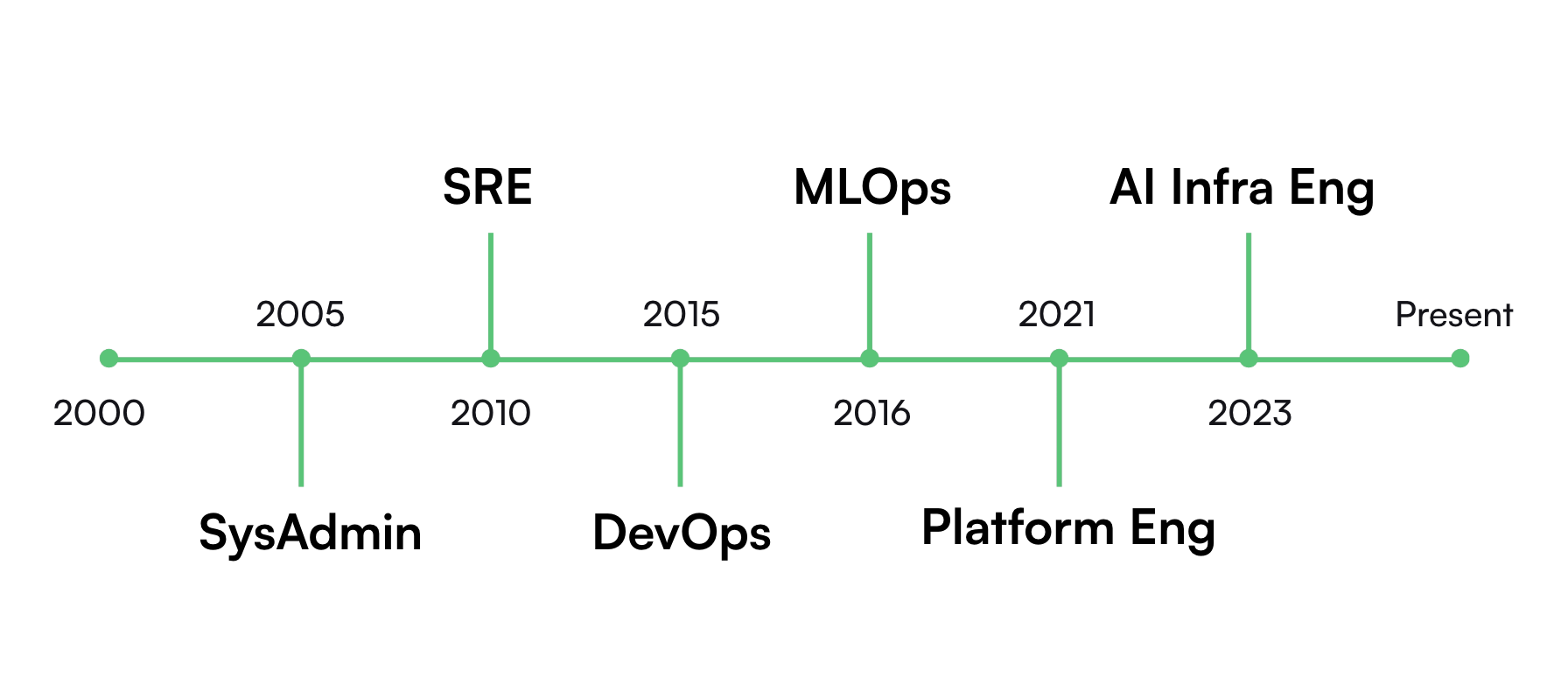
By 2025, companies like OpenAI, Anthropic, Meta (and Amazon‘s newly emphasized AGI effort) had dedicated AI infrastructure orgs distinct from traditional platform teams. The skills crossed over from high-performance computing, systems research, and cloud scaling. The same DNA that once powered scientific computing now fuels generative intelligence.
The world had better models. It needed better infrastructure to keep those models alive.
Day in the Life: Half Firefighter, Half Architect
At most AI companies today, mornings begin with dashboards. GPU utilization charts, latency metrics, inference queue depths. These are quiet indicators that everything is running (or that something very soon won’t be).
The AI Infrastructure Engineer’s day starts there. A spike in memory usage on one cluster might mean a new model deployment isn’t scaling correctly. A sudden jump in inference time could trace back to an unbalanced batch size or a missing cache layer.
They move quickly, debugging with precision and restraint, aware that every minute of downtime burns compute and money.
The rest of the morning often involves collaboration: syncing with the AI engineering team that’s pushing a new fine-tuned model into production. They discuss GPU allocation, container images, rollout thresholds, and the handoff from staging to live traffic.
In theory, these should be automated workflows. In practice, every model behaves differently, and production always has its surprises.
“Every new deployment is an experiment,” said one infra lead. “You can simulate load all you want, but nothing compares to real users hammering the system.”
Afternoons are usually quieter but more exacting. Once the fires are out, engineers turn to cost and performance optimization. They go over usage reports, looking for idle GPU time, or jobs that could be offloaded to cheaper regions.
A few configuration tweaks might cut latency by 50 milliseconds or save thousands in compute fees. Those improvements rarely make headlines, but they compound — every optimization translates directly to uptime and efficiency.
By evening, many write automation scripts to eliminate the manual steps that tripped them up earlier. Infrastructure work rewards those who are both reactive and anticipatory: you fight fires until you can automate them out of existence.
“It’s not glamorous,” another engineer said. “You don’t see our names in the release notes. But if we stopped doing our job, every model would go dark within hours.”
That, more than anything, defines the role.
AI Infrastructure Engineers exist in the narrow space between speed and stability — fast enough to keep innovation moving, careful enough to make sure it doesn’t collapse under load.
Their work rarely trends on social media. But every smooth model demo, every low-latency API call, every seamless rollout owes something to the people behind those dashboards.
Market Demand, Jobs & Compensation
Search any major job board in 2025 and you’ll find a pattern emerging. Companies from early-stage startups to defense contractors are all hiring for AI Infrastructure Engineers.
Like all the other jobs profiled in this blog series, titles vary for this one, too — AI Platform Engineer, ML Infrastructure Engineer, AI Platform Engineering, and AI Systems Engineer — but the substance is nearly identical.
Pretty much every listing describes a hybrid role combining the reflexes of a DevOps veteran with the mathematical literacy of a machine learning engineer. One job post calls for “experience orchestrating massive GPU clusters to process petabytes of multimodal data.” Another asks for “hands-on knowledge of PyTorch, CUDA, and Ray, with a strong focus on inference cost optimization and distributed training.”
Whether the focus is training self-driving perception systems, managing high-throughput inference APIs, or building multimodal data pipelines, each role I’ve seen emphasizes the same skill set: systems reliability, GPU orchestration, and cost-aware scaling. Experience with Kubernetes, Terraform, and cloud providers like AWS and GCP is taken for granted — what sets candidates apart now is fluency with modern serving and orchestration stacks such as Ray, Triton, and vLLM — tools widely used for distributed training and high-throughput inference.
In short, these companies want someone who can turn compute into intelligence — reliably, repeatably, and without bankrupting the company.
“Two years ago, this title didn’t even exist on most hiring plans,” said one recruiter who specializes in technical placements. “Now I have clients offering half a million total comp packages for candidates who can keep inference costs under control.”
Part of the surge comes from the hardware bottleneck. As GPU supply chains tighten and inference costs climb, companies are discovering that infrastructure is a competitive advantage. An efficient cluster configuration can cut millions from annual compute bills, and that efficiency only comes from engineers who understand both the code and the silicon.
The breadth of industries hiring tells its own story. Autonomous vehicles, robotics, SaaS, cloud infrastructure, even consulting firms — all are seeking AI Infrastructure talent. They’ve realized that without this layer, every AI initiative risks collapsing under the weight of its own compute.
What’s striking isn’t just demand. It’s visibility. These jobs are no longer buried in the back pages of “Platform Engineering.” They’re headline listings, often commanding the same salary range as senior AI researchers. It’s the clearest sign yet that infrastructure has become strategic, not supportive.
A look at compensation for infra engineers
AI infrastructure has officially entered top-tier compensation territory. At the frontier labs, total packages now rival or exceed those of AI researchers. At mainstream companies, pay bands have climbed enough to pull seasoned DevOps and SRE talent into the AI ecosystem.
Across major job boards, listings for AI infrastructure-type roles have climbed markedly in 2024–25, reflecting broad demand. Salaries that once capped at $180,000 are now pushing $300,000+ for senior-level engineers, especially inside AI-first organizations. Even mid-market enterprises — from SaaS platforms to healthcare analytics firms — are offering $160,000 and above for talent who can keep their AI pipelines reliable.
At the very top, frontier lab compensation blurs the line between salary and venture capital. Crowd-sourced data shows OpenAI software-engineer total comp ranging from about $242K (L2) to roughly $1.3M (L6), with a median around $910K. At Anthropic, recent submissions put software-engineer total comp with a median around $570K and upper ranges in the $650K ballpark.
Below that stratosphere, the market is steadier but still strong. Aggregated data from Glassdoor and other trackers places AI/ML infrastructure roles well above traditional platform engineering and close to applied ML. Glassdoor’s ‘AI Infrastructure Engineer’ page currently lists an average U.S. total pay around $166K with the 90th percentile near $255K (limited sample, but directionally useful).
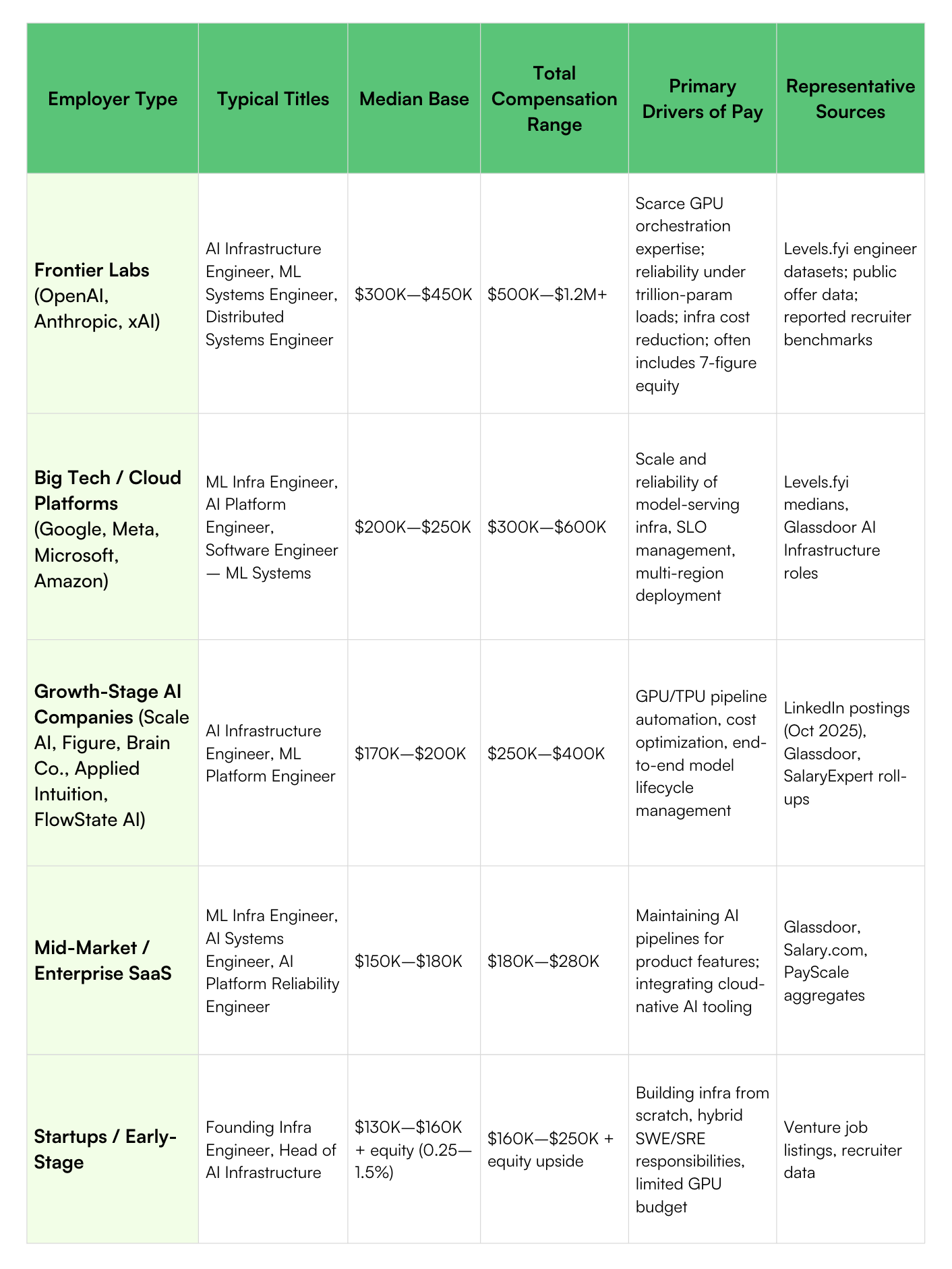
All of it reflects the same dynamic: a widening talent war for people who can bridge distributed systems with model lifecycles. As AI companies scale, infra engineers are being pulled into the same compensation bands once reserved for elite ML researchers — proof that in this era, reliability and orchestration are as strategically valuable as breakthroughs themselves.
The Quiet Backbone
Every technological revolution has an invisible architecture beneath it. The steam engine had its ironworks. The internet had its fiber and servers. The AI revolution runs on infrastructure and the people who build it.
AI Infrastructure Engineers are not inventing new models or algorithms; they are inventing the conditions under which intelligence can exist at scale. They make decisions that determine whether a model that dazzled in a lab can survive contact with millions of users, unpredictable data, and finite compute.
In most AI companies, these engineers now occupy the junction where ambition meets physics. They understand how transformer architectures translate into GPU memory footprints, how inference workloads stress the network stack, how small changes in precision or quantization can swing cloud costs by millions. They design systems resilient enough to run AI continuously — not as experiments, but as infrastructure as dependable as electricity.
“At some point, AI stops being code,” said one veteran infra engineer. “It becomes logistics — data, compute, throughput. You stop thinking in lines of Python and start thinking in megawatts.”
This shift is changing the hierarchy of influence inside the industry. AI research still drives discovery, but it’s infrastructure that defines feasibility. Companies that can run large models cheaply and reliably now possess a strategic advantage as decisive as algorithmic breakthroughs. That’s why the best infrastructure engineers are recruited with the same intensity once reserved for machine learning scientists.
Their craft also reflects a new kind of engineering philosophy: operational intelligence. It’s no longer enough to design systems that work; they must adapt, balance, and evolve in real time. Every model deployment teaches new lessons about how to orchestrate data, containers, and GPUs more intelligently. Over time, infrastructure itself becomes a learning system — the silent intelligence behind intelligence.
“People see the demo,” another engineer said. “We see the scaffolding that holds it up.”
As the world rushes to integrate AI into everything — search, code, medicine, logistics — these scaffolds are becoming the foundation of the digital economy. Reliability and efficiency are not afterthoughts; they are the new frontiers of innovation. An AI product that fails to scale or bankrupts its cloud budget is not a product at all.
When the hype around models inevitably fades, what will remain are the systems that endured. The clusters, the pipelines, the orchestration logic, and the engineers who built them. They will be remembered less for what they invented than for what they enabled: a world where artificial intelligence could finally become a real, usable, global technology.
In the end, that’s the true story of this era:
The breakthroughs may belong to researchers, but the durability of the AI age will belong to its infrastructure. The AI Infrastructure Engineer is quietly upholding the foundation for the AI era.
Conclusion
Every wave of innovation has its unseen architects. In the age of artificial intelligence, they sit behind dashboards, tuning the flow of computation instead of drafting research papers. Their work determines which ideas stay experiments and which become products that the world can use.
They manage the pulse of machines that never sleep and systems that must never fail. When the headlines move on to the next breakthrough, they will still be here, keeping the lights of intelligence on. History will remember the discoveries, but it will run on their infrastructure.
Handpicked Related Resources:
- From Palo Alto to the Pentagon: Why Every Company Suddenly Wants AI Engineers
- The AI Researcher Arms Race: Inside Tech’s Priciest Talent War
- The Great Return to Work: Hybrid Roles & New Normal of Silicon Valley Startupland